Tech
What Is Data Scraping? Learn Data and Web Scraping Basics

Data is the bloodline, and so does data scraping!
In our increasingly data-driven world, the value of information cannot be underestimated. The abundance of online data has made it essential for businesses, researchers, and individuals to extract and analyze relevant information. This is where data scraping comes in.
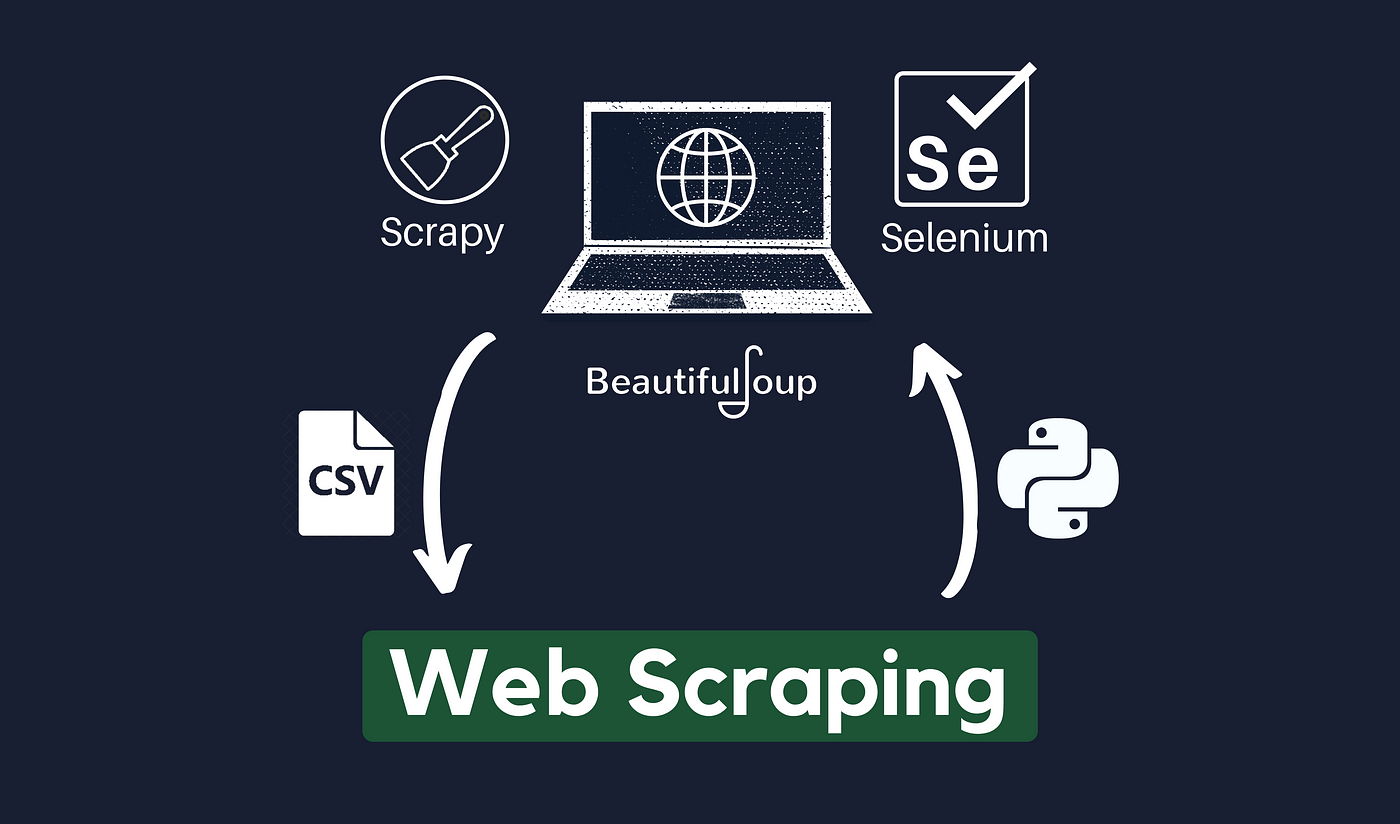
Web scraping is an automated technique used to extract data from websites. Using specialized software or programming methods, web scraping enables the data collection from web pages, converting it into a structured format for further analysis and interpretation.
Its popularity stems from its ability to gather large volumes of data from diverse sources efficiently. This article will look at the fundamentals of data scraping, including the techniques used.
Reason Why the Whole World is Behind Data?
The fascination with data on a global scale stems from its incredible potential to drive transformation. Data empowers businesses by providing the necessary information to make well-informed decisions, gain valuable insights, and identify important trends. Its applications are limitless, from conducting market research and competitive analysis to comparing prices and tracking sentiment. Researchers heavily rely on data to discover new insights, validate their hypotheses, and push the boundaries of scientific knowledge.
As a result, the pursuit of data is relentless worldwide, and data scraping plays a crucial role in this pursuit. Data scraping opens the door to a vast pool of data that fuels analysis, research, and the development of data-driven solutions by extracting valuable information from websites. It empowers individuals, businesses, and researchers to stay at the forefront of their respective fields by harnessing the power of data and leveraging its potential.
What is Data Scraping? Is Data Scraping Legal?
Data scraping, or web scraping, is a vital technique developers use to automate data extraction from websites. It includes programmatically recovering and parsing HTML or XML code to extract specific information, analysis, storage, or further processing. Scraping scripts are created by developers using various tools and coding languages to traverse through web pages, locate relevant data pieces, and extract them in an organized way.
This extracted data can then be utilized for various applications, including research, lead generation, price comparison, content aggregation, and monitoring. Data scraping/Web scraping empowers developers to efficiently collect and leverage data from the Web, enabling them to create innovative solutions and drive data-driven decision-making.
Moreover, the legality of data scraping depends on factors such as jurisdiction and the purpose of scraping. It is important to review and comply with a website’s Terms of Service. Additionally, scraping copyrighted content can raise legal concerns.
Is Data Scraping Similar to Data Crawling?
Crawling is the process undertaken by large search engines like Google, where their robot crawlers (such as Googlebot) explore the internet to index web content. On the other hand, scraping is focused on extracting data from a specific website.
Here are three key differences in the behavior of scraper bots compared to web crawler bots:
- Pretending to be web browsers: Scraper bots often mimic web browsers to deceive websites, while crawler bots indicate their purpose and do not attempt to misrepresent themselves.
- Advanced actions: Scrapers may perform advanced actions like filling out forms or engaging in specific behaviors to access certain parts of a website. In contrast, crawlers typically do not engage in such actions and simply crawl and index web pages.
- Ignoring robots.txt: Scrapers usually disregard the instructions specified in the robots.txt file, which is intended to guide web crawlers on which data to parse and which areas of the site to avoid. Since scrapers are designed to extract specific content, they may ignore directives intended to exclude certain data from being scraped.

Three Steps in Scraping Website Data
Web scraping involves a three-step process, which can be conceptually simple yet technically intricate:
- The scraper bot, implemented as code, initiates an HTTP GET request to a targeted website, retrieving the desired information.
- Upon receiving a response from the website, the scraper analyzes the HTML document, carefully extracting the required data based on a predefined pattern.
- Finally, the extracted data transforms and is converted into the intended format as designed by the author of the scraper bot.

What Is the Prime Goal of Data Scrapping?
Scraper bots serve various purposes, including:
- Content scraping: These bots extract content from websites, enabling the replication of unique features or advantages of a specific product or service. For instance, a competitor may scrape review content from platforms like Yelp and reproduce it on their site, falsely presenting it as original content.
- Price scraping: Competitors employ scraper bots to gather pricing data, allowing them to aggregate information about their rivals. This enables them to formulate competitive strategies and gain a unique advantage in the market.
- Contact scraping: Scraper bots can extract contact details from websites, such as e-mail addresses and phone numbers. This information can be used to create bulk mailing lists, conduct robocalls, or engage in malicious social engineering attempts. Spammers and scammers often rely on contact scraping to find new targets for their activities.
How to Do Data Scraping: Top Data Scraping Techniques
So how to scrape data from a website?
Understanding various data scraping techniques can significantly enhance your ability to extract data from a website. Using the following scraping techniques, you can effectively retrieve data from websites, empowering you to create robust and data-driven applications.
Here are some commonly used techniques for data scraping:
HTML Parsing: With this data scraping technology, the HTML structure of a web page is parsed using tools like Python’s BeautifulSoup or JavaScript’s Cheerio. You can explore the parsed HTML tree to find specific elements, such as tags, classes, or IDs, and extract the appropriate data.
XPath Queries: A language called XPath is used to pick elements from an XML or HTML document. Using XPath expressions, you can accurately target and extract data from particular points inside the document structure. Libraries like lxml in Python and XPath.js in JavaScript offer convenient XPath querying capabilities.
CSS Selectors: Like XPath, CSS selectors let you focus on particular HTML elements by class name, ID, or element type. You can use libraries like PyQuery in Python or jQuery in JavaScript to utilize CSS selectors for data extraction.
API Scraping: For accessing the data, some websites offer APIs. In these circumstances, you can communicate directly with the API endpoints by submitting queries and requesting data in a structured format, such as JSON or XML. For data extraction, this strategy is frequently more dependable and effective.
Headless Browsers: Selenium and Puppeteer are examples of headless browsers that mimic the actions of real web browsers. They make it possible to interact with websites by running JavaScript, pressing buttons, and completing forms. This method is suitable for data scraping from dynamic websites relying on JavaScript.
Rate Limiting and Proxies: Implementing strategies like rate restriction (regulating the frequency of requests) and proxy Scraper (changing between several IP addresses) is crucial to prevent being blacklisted or restricted by websites. This promotes a dignified scraping procedure.
That’s all about how to pull data from a website!

How to Mitigate Web Scraping?
To mitigate web scraping, developers can significantly reduce the effectiveness of web scraping and protect their websites and data from unauthorized access and misuse.
Let’s have a look at these helpful strategies:
Implement rate limiting: Limit the number of requests per IP address or impose rate limitations on API endpoints to stop excessive scraping.
Use CAPTCHA or reCAPTCHA: Integrate CAPTCHA or reCAPTCHA challenges to distinguish between human users and bots in critical areas of your website.
User-agent verification: Incoming requests should have their user agents checked to spot any odd or suspicious patterns. Block requests using user agents that are erroneous or suspicious.
IP blocking: Incoming requests should be watched, and IP addresses that make repeated requests or access restricted sections should be blocked.
Implement session management: Demand that users log in or use authentication tokens. Keep an eye on session activity and stop shady sessions.
Obfuscate HTML structure: Use arbitrary class or ID identifiers to alter the HTML structure of online pages, making it more difficult for data scrapers to find and extract. Use a content delivery network (CDN) to spread website material over several servers, making it more difficult for scrapers to focus on a single server.
Use JavaScript challenges: Implement JavaScript obstacles that prevent easy scraping methods by requiring client-side scripts to be executed to render or interact with page content.
Monitor access logs: Examine server access logs frequently to look for odd patterns, frequent queries, or traffic spikes that might point to scraping activity.
Legal measures: Web scraping should be explicitly prohibited in terms of service, and where necessary, malicious scrapers should be dealt with legally.

Top Data Scraping Tools in Market
#1. Zenscrape
Bright Data, Apify, ParseHub, and many more, the market is flooded with a plethora of options when it comes to finalizing the best data-scrapping tools. Where they all come with their own exceptional features and restrictions, Zenscrape’s unparalleled flexibility and advanced technology help developers to scrape huge data in seconds, making all the other options a cloud of dust!
It offers a range of features and functionalities that make it a popular choice among data enthusiasts. Some key features of Zenscrape include:
- Ease of Use: Zenscrape provides a user-friendly interface that simplifies the data scraping process, allowing users to extract data effortlessly.
- Web Scraping APIs: Zenscrape offers robust APIs that enable seamless integration with various programming languages, making it convenient for developers.
- Proxy Support: The tool supports proxy rotation, ensuring efficient and anonymous data scraping without IP blocking or restrictions.
- Advanced Scraping Capabilities: Zenscrape supports dynamic content rendering, JavaScript execution, and handling of CAPTCHAs, enabling the scraping of complex websites.
- Data Quality and Reliability: Zenscrape ensures high-quality and accurate data extraction, providing reliable results for various scraping needs.
With its comprehensive features, Zenscrape proves to be a reliable and efficient tool for data scraping, catering to the requirements of businesses, researchers, and developers alike. However, depending on the size and requirements of your business, there are other options you can rely upon to save your money!
#2. Zenserp
Zenserp is a data scraping tool that specializes in retrieving search engine result pages (SERPs) data. It allows users to extract valuable information from search engines such as Google, Bing, and Yahoo.
Here are some key features of Zenserp:
- Supports various search engines, including Google, Bing, and Yahoo.
- Provides access to structured data like organic search results, featured snippets, related searches, and more.
- Offers options to scrape data at scale with high performance and accuracy.
- Enables integration with other tools and platforms through APIs.
- Provides comprehensive documentation and customer support.
Pricing: Zenserp offers a range of pricing plans starting from $49/month. They also provide a free trial with limited access to their features.
#3. Bright Data (formerly Luminati)
Bright Data is a powerful data collection platform that offers comprehensive scraping solutions. It provides a wide range of scraping capabilities and advanced features for various use cases.
Here are some notable features of Bright Data:
- Offers a global proxy network with millions of residential IPs for anonymous and reliable scraping.
- Supports data extraction from websites, search engines, e-commerce platforms, social media, and more.
- Provides advanced data manipulation and filtering options.
- Offers browser automation tools for dynamic website scraping.
- Provides detailed analytics and monitoring to track scraping performance.
Pricing: Bright Data offers customized pricing based on specific requirements. They do not offer a free plan but provide a free trial with limited access to their services.
Please note that pricing details and free plan availability might change over time, so it’s recommended to visit the respective websites for the most up-to-date information.
Final Verdict
In today’s era of data dominance, web scraping has emerged as an indispensable technique, acting as a digital key to unlocking valuable insights from websites. By automating data extraction, web scraping saves precious time and effort and opens doors to a vast repository of information that may otherwise remain hidden behind APIs. This powerful method empowers developers to pioneer innovative solutions, make informed choices, and embark on data-driven journeys.
FAQs
What Is Data Scraping?
Data scraping, or web scraping, is an automated technique to programmatically extract specific information from websites by parsing HTML or XML code. It’s used for research, lead generation, and content aggregation.
Why Is Web Scraping Important?
Web scraping unlocks inaccessible information, automates data collection, and accelerates research, analysis, and solution-building. It empowers developers with invaluable insights, personalized recommendations, and machine-learning capabilities.
How Can Web Scraping Be Mitigated?
To counter web scraping, employ rate limiting, CAPTCHA challenges, user-agent verification, IP blocking, session management, HTML obfuscation, JavaScript challenges, access log monitoring, and legal measures. Safeguard websites and data from unauthorized scraping.

Tech
US: A Judge Mandates that Google Allow Competing App Stores to Access Android

(VOR News) – The ruling is that Google, the greatest technology firm in the world, is required to make its Android smartphone operating system available to merchants that supply applications that are in direct rivalry with Google’s. This decision was reached by a judge in the United States of America.
The Android Play store, which is owned and operated by Google, was found to be an example of an illegal monopoly arrangement by a jury in the state of California on Monday. The finding was reached by a jury. Monday is the day that this decision was come to.
An earlier federal judge ruled Google’s search engine illegal.
This finding, which came after that decision, has forced the company to suffer yet another setback. As a result of the corporation having already encountered its initial obstacle, this decision has been established. This particular decision was made by the judge during the month of August, when the month was in progress.
In light of the fact that the decision was made, what exactly does it mean that the choice was accepted?
In accordance with the verdict, Google is obligated to make it possible for users to download Android app stores that are offered by third-party competitors. For a period of three years, the corporation is prohibited from imposing restrictions on the usage of payment mechanisms that are integrated into the application.
In addition, it is important to keep in mind that Google does not possess the right to impose restrictions on the utilization of ways to make payments online.
Additionally, the verdict makes it unlawful for Google to give money to manufacturers of smartphones in order to preinstall its app store. Smartphone manufacturers are prohibited from doing so.
Furthermore, it prevents Google from the possibility of sharing the revenue that is generated by the Play store with other companies that are in the industry of delivering mobile applications.
In addition to this, the court has mandated the establishment of a technical committee that will be made up of three different people chosen at random.
The committee will be responsible for monitoring the implementation of the reforms and finding solutions to any disagreements that may occur as a consequence of the implementation of the reforms while they are being implemented. This task will fall under the committee’s purview so that it may fulfill its duties.
However, certain components were allowed to be put into action until July 1st, despite the fact that the judge’s statement suggested that the ruling would take effect on November 1st. The statement was the basis for the ruling, which ultimately became effective.
Particularly, I wanted to know what Google’s reaction would be.
There is a fact that Google does not adhere to this directive, which has been brought to their attention. This document argued that the alterations that the judge had ordered to be made would “cause a range of unintended consequences that will harm American consumers, developers, and device makers.”
The judge had ordered the modifications to be implemented. The alterations were to be carried out as indicated by the judge’s ruling. The judge made it clear that he expected these revisions to be carried out in accordance with his guidance.
The company’s regulatory affairs vice president, Lee-Anne Mulholland, provided the following statement: “We look forward to continuing to make our case on appeal, and we will continue to advocate for what is best for developers, device manufacturers, and the billions of Android users around the world.”
On average, over seventy percent of the total market for smartphones and other mobile devices is comprised of mobile devices that are powered by the Android operating system. Both smartphones and other small mobile devices are included in this category.
In the event that the Play app store continues to be shown on the home page and that other Google applications are pre-installed prior to the installation of the Android application, smartphone manufacturers are entitled to install the Android application at no cost at their discretion.
Additionally, the Android application can be installed on devices that are manufactured for smartphones.
SOURCE: DWN
SEE ALSO:
Over The Planned “Link Tax” Bill, Google Threatens to Remove NZ News Links.
Tech
WhatsApp Now Features a “Mention” Tool for Status Updates and Stories.

(VOR News) – Those who use WhatsApp now have the ability to mention other people in their stories or status updates as a consequence of a feature that was only recently enabled on the platform.
Previous to this point, this capability was not available. It wasn’t until quite recently that this capability became available to the public.
According to the information that was provided by the company, users now have the opportunity to tag close friends in their stories, and the person who is mentioned will have the option to go back and re-share an earlier version of that story. This information was provided by the company. The corporation was kind enough to reveal this information to us.
Because of a new feature that has been added to the WhatsApp app, users now have the opportunity to like individual stories and status updates.
This capability was previously unavailable to WhatsApp users.
A significant amount of progress has been made in this context. Alternative readers now have the chance to “like” a work, which is comparable to liking a post on Facebook. This feature was introduced in recent years. When compared to the past, this is a tremendous shift.
At one point in time, viewers were only permitted to observe the total number of views that a particular story had gotten. These restrictions were eliminated in later versions of the software.
Additionally, it is essential that the likes and reactions to a story be kept anonymous during the entire process. One of the factors that contributes to the general mystery that surrounds this characteristic is the fact that this is one of the elements.
The person who brought it to the attention of others is the only person who will be able to judge who enjoyed it and who did not care about it. These individuals will be able to make this determination.
A notification will be issued to the individual who was referenced earlier in the sentence and who was named in the story or status update that was discussed. A notification of this nature will be sent to the individual via WhatsApp.
This message will be sent to the user in question whenever that person makes a reference to another person while they are in the process of elaborating on a narrative or updating their status. You will receive a notification alerting you that you have been tagged in the narrative.
This notification will be delivered to the person who receives this message. In addition, students will be provided with the opportunity to re-share the tale for themselves.
It is important to note that if the names of individuals who have been referenced in a narrative or a status update are included in any of these, then the names of those individuals will not be accessible to any third party through any of these. In light of the fact that the identities of those individuals will be concealed from public disclosure, this is the condition that will be required.
While WhatsApp recently made the announcement that it will be incorporating this functionality, it is highly likely that not all users will have access to it at the same time.
This is despite the fact that WhatsApp recently made this announcement.
Despite the fact that WhatsApp has only recently made a public announcement that it will move forward with the deployment, this is the situation that has presented itself.
As soon as a short period of time has elapsed, access will be made available to each and every person on the entire world.
Additionally, WhatsApp has hinted that new functionalities might be introduced to the status and updates tab in the future months.
The purpose of these capabilities is to provide users with assistance in maintaining healthy connections with the individuals who play a vital role in their living experiences. This is done in order to give users with support in maintaining close relationships with the folks who are the subject of the inquiry.
It is with the purpose of supporting users in successfully keeping close ties with the individuals in question that this step is taken.
SOURCE: DN
SEE ALSO:
Over The Planned “Link Tax” Bill, Google Threatens to Remove NZ News Links.
Accenture and NVIDIA Collaborate to Enhance AI Implementation.
Tech
Over The Planned “Link Tax” Bill, Google Threatens to Remove NZ News Links.

(VOR News) – Google has sent a strong message to the New Zealand government, threatening to stop boosting local news content should the Fair Digital News Bargaining Bill become law.
The law, put up by the Labour government and backed by the coalition in power at the moment, mandates that digital companies such as Google pay back news organizations for links to their material.
News publishers, on the other hand, charge the tech giant with “corporate bullying.”
Google says this measure may have unanticipated effects.
Google New Zealand’s country director, Caroline Rainsford, voiced her worries that the law, which is being referred to as a “link tax,” is not doing enough to support the media industry in New Zealand right now.
She underlined that Google would have to make major adjustments if the previously mentioned law were to pass, including cutting off links to news articles from its Search, News, and Discover platforms and cutting off financial ties with regional publications.
According to Rainsford, similar legislation has been proposed and approved in other nations including Australia and Canada, but it has not been proven to be effective there and breaches the principles of the open web.
She drew attention to the fact that smaller media outlets will be most negatively impacted, which will limit their capacity to reach prospective audiences.
Google says its alternative options will protect smaller, local media from negative effects.
Conversely, it conveys apprehension regarding the possible fiscal obligations and vagueness of the legislation, which it feels generates an intolerable level of ambiguity for enterprises functioning within New Zealand.
The New Zealand News Publishers Association (NPA) has reacted to Google’s warnings by alleging that the internet behemoth is using coercive tactics.
They specifically contend that the need for regulation stems from the market distortion that Google and other tech giants have created, which has fueled their expansion into some of the most significant corporations in global history.
The legislation aims to create a more equal framework that media businesses can use to negotiate commercial relationships with technological platforms that profit from their content.
New Zealand Media Editors CEO Michael Boggs stated that he was in favor of the bill, citing the fact that Google now makes a substantial profit from material created by regional publications.
He also emphasized that the use of artificial intelligence by Google—which frequently makes references to news articles without giving credit to the original sources—highlights the significance of enacting legislation.
Paul Goldsmith, the Minister of Media and Communications, has stated that the government is now evaluating various viewpoints and is still in the consultation phase.
He stated that the government and Google have been having continuous talks and will keep up these ongoing discussions.
However, not all political parties accept the validity of the Act.
The ACT Party’s leader, David Seymour, has voiced his displeasure of the proposal, saying that Google is a game the government is “playing chicken” with. He threatened the smaller media companies, saying that they would suffer from worse search engine rankings if the internet giant followed through on its promises.
Seymour contended that it is not the government’s responsibility to shield companies from shifts in the market brought about by consumer preferences.
The things that have happened in other nations are similar to what has happened in New Zealand.
Google has agreements with a number of Australian media firms that are in compliance with its News Media Bargaining Code. These agreements contain provisions that permit an annual cancellation of these agreements.
Due to the government’s decision to exempt Google from the Online News Act, the company has committed to supporting news dissemination by contributing annually to the Canadian journalistic community.
The New Zealand measure is consistent with global approaches aimed at regulating the relationships that exist between technology corporations and media organizations.
It’s hard to say what will happen with the Fair Digital News Bargaining Bill as the discussion goes on. Google and the New Zealand media landscape are preparing for what might be a protracted legal battle.
SOURCE: TET
SEE ALSO:
Accenture and NVIDIA Collaborate to Enhance AI Implementation.
-

 News4 years ago
News4 years agoLet’s Know About Ultra High Net Worth Individual
-
Entertainment2 years ago
Mabelle Prior: The Voice of Hope, Resilience, and Diversity Inspiring Generations
-
News11 years ago
Enviromental Groups Tell Mekong Leaders Lao Dam Evaluation Process Flawed
-
 Health4 years ago
Health4 years agoHow Much Ivermectin Should You Take?
-

 Tech3 years ago
Tech3 years agoTop Forex Brokers of 2023: Reviews and Analysis for Successful Trading
-

 Lifestyles3 years ago
Lifestyles3 years agoAries Soulmate Signs
-

 Entertainment3 years ago
Entertainment3 years agoWhat Should I Do If Disney Plus Keeps Logging Me Out of TV?
-

 Health3 years ago
Health3 years agoCan I Buy Ivermectin Without A Prescription in the USA?